Distributed training with PyTorch
For batch jobs, some frameworks like PyTorch, Tensorflow, and Horovod support distributed training. Lepton also supports distributed training for these frameworks.
Here is an example for running a distributed PyTorch job with 2 workers on Lepton.
Prepare the Python script for distributed training
As an example, this script implements distributed training of a convolutional neural network (CNN) on the MNIST dataset using PyTorch's DistributedDataParallel (DDP) to leverage multiple GPUs in parallel.
Use a text editor and copy the following code over, save it as train.py.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torch.distributed as dist
from torchvision import datasets, transforms
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, DistributedSampler
class MNISTModel(nn.Module):
def __init__(self):
super(MNISTModel, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def train(rank, world_size):
print(f"Running on rank {rank}.")
dist.init_process_group("nccl", rank=rank, world_size=world_size)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank)
train_loader = DataLoader(dataset, batch_size=64, sampler=sampler)
model = MNISTModel().to(rank)
model = DDP(model, device_ids=[rank])
optimizer = optim.Adam(model.parameters(), lr=0.001)
model.train()
for epoch in range(1, 11):
sampler.set_epoch(epoch)
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(rank), target.to(rank)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 10 == 0:
print(f"Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} ({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}")
if rank == 0:
torch.save(model.module.state_dict(), "mnist_model.pth")
print("Model saved as mnist_model.pth")
dist.destroy_process_group()
def main():
world_size = torch.cuda.device_count()
torch.multiprocessing.spawn(train, args=(world_size,), nprocs=world_size, join=True)
if __name__ == "__main__":
main()
Upload the script to Lepton
You need to save and upload the script to the Lepton file system, assuming you've saved it as train.py, just run the following command to upload it to a directory of your Lepton workspace, let's use /distributed-training-demo as an example.
lep storage upload train.py /distributed-training-demo/train.py
You can also upload the scripts through the Dashboard UI:
- Navigate to the File System page in the Dashboard.
- Create a new folder named
distributed-training-demo. - Click on Upload File button and choose From Local - Web.
- Select the
train.pyfile to upload.

Create Job through Dashboard
Head over to the Batch Jobs page, and follow the steps below to create a job.
Set up the job
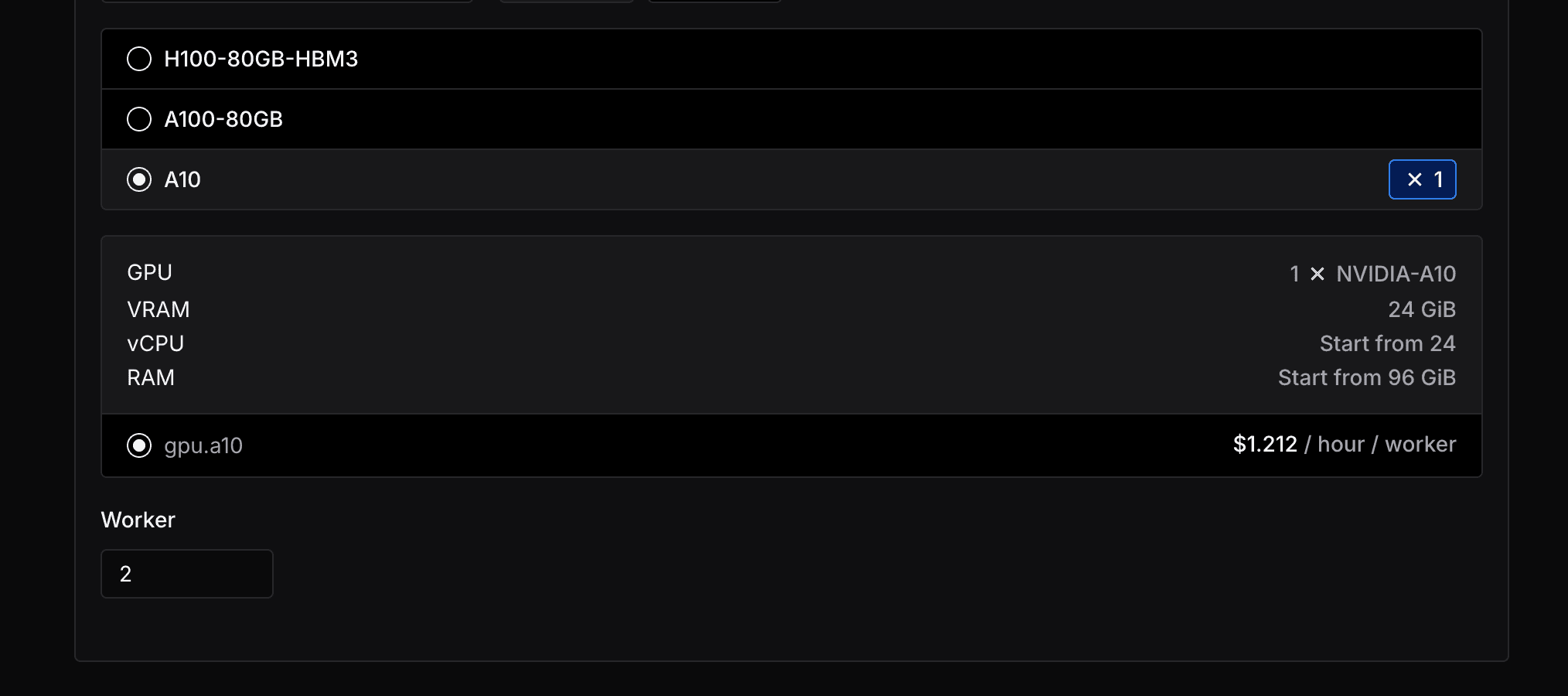
Resource
In the resource section, first, you can select which node group do you want to use. By default, you can use the on-demand node group, which is shared by all users.
Or you can select your dedicated node group for better performance and isolation.
Node group feature is only available for the Enterprise plan, you can contact us for applying your own node groups.
Select the resource type you want to use, for example, A10, and set the number of workers to the desired number.
In this guide, we want to use 2 replicas, so we set the number of workers to 2.
Container
In the container section, use the default image and paste the following command as the start command to run the job:
# Download the environment setup script from Lepton's GitHub repository, make it executable, and source it to initialize the environment variables.
wget -O init.sh https://raw.githubusercontent.com/leptonai/scripts/main/lepton_env_to_pytorch.sh;
chmod +x init.sh;
source init.sh;
# Print the environment variables and list the files in the root directory to verify the setup.
env | grep RANK;
ls -al /;
# Run the distributed training script.
python -m torch.distributed.run \
--nnodes=$WORLD_SIZE \
--nproc_per_node=1 \
--node_rank=$NODE_RANK \
--master_addr=$MASTER_ADDR \
--master_port=$MASTER_PORT \
/mnt/train.py
File system mount
In the file system mount section in the Advanced configuration section, click on the Add file system mount button to add a mount path.
Select path /distributed-training-demo for the Mount from part, as we just uploaded out Python script to the coressponding directory, and specify /mnt as the Mount as part.
Create and Monitoring
Now you can click on the Create button to create and run the job. After that, you can go to check the job logs or details to monitor the job.
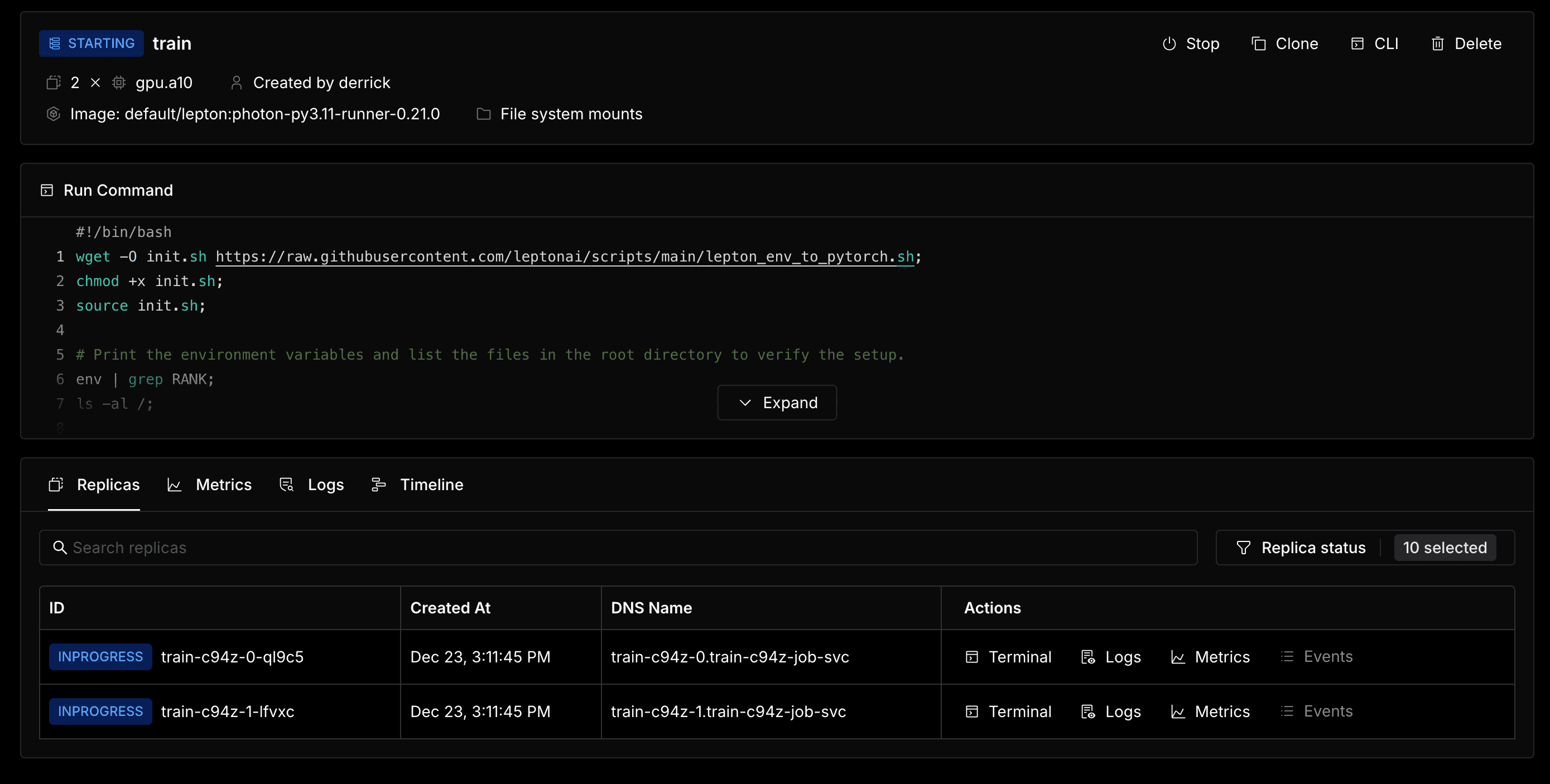
Within the job details page, you can see the status of each worker and the logs of each worker. You can also use Web Terminal to connect to the worker node and check the status of the worker as well.
What's next?
Once the job is finished, you can see the job with a "Completed" state, and you can access the trained model file in the storage page.