SDXL Fine-Tuning on Lepton
Lepton jobs are designed for the efficient execution of long-running tasks, making it ideal for handling processes like model fine-tuning. In this guide, we'll walk you through using Lepton's job to streamline SDXL fine-tuning, improving team productivity and workflow. Let's dive in!
Step 1: Preparing an Output Directory for Fine-Tuning
To begin, create a folder within your Lepton workspace to store the fine-tuning results. You will later mount this folder as the output directory when configuring the fine-tuning job.
- Go to your workspace storage page.
- In the action bar, click New Folder, and name it to reflect your task. For this example, it can be
sdxl-finetune.
Step 2: Configuring Your Job
- Navigate to the Create Batch Job page.
- Name your job, such as
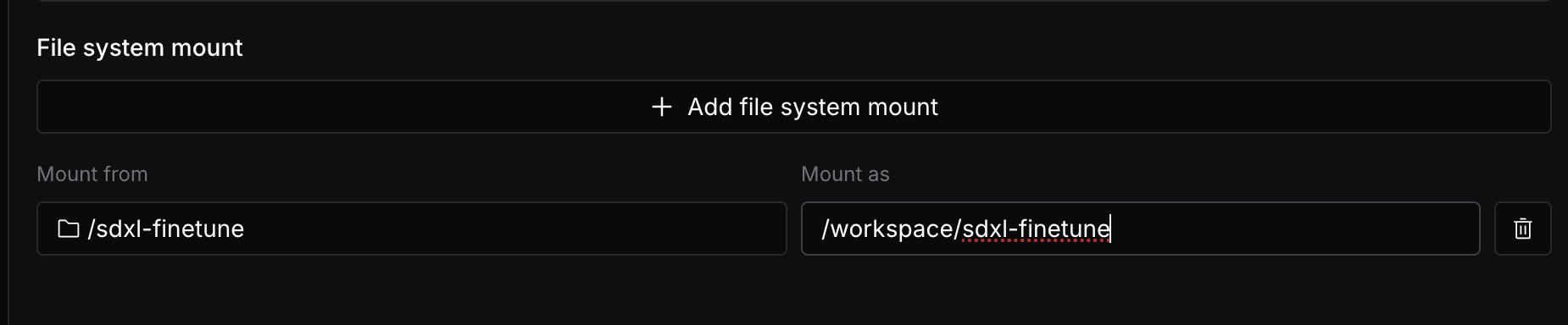
sdxl-finetune-job, and choose a resource type suitable for your task. For SDXL fine-tuning, we’ll selectH100as we’ll be using an H100 GPU. - Head over to Advanced Settings. In the File system mount section, click on Add file system mount button, select Mount from as the folder name you just created(sdxl-finetune for this example), and for Mount as, input
/workspace/sdxl-finetune. This ensures that the fine-tuned model will be stored in the correct directory.
Step 3: Specifying the Fine-Tuning Command
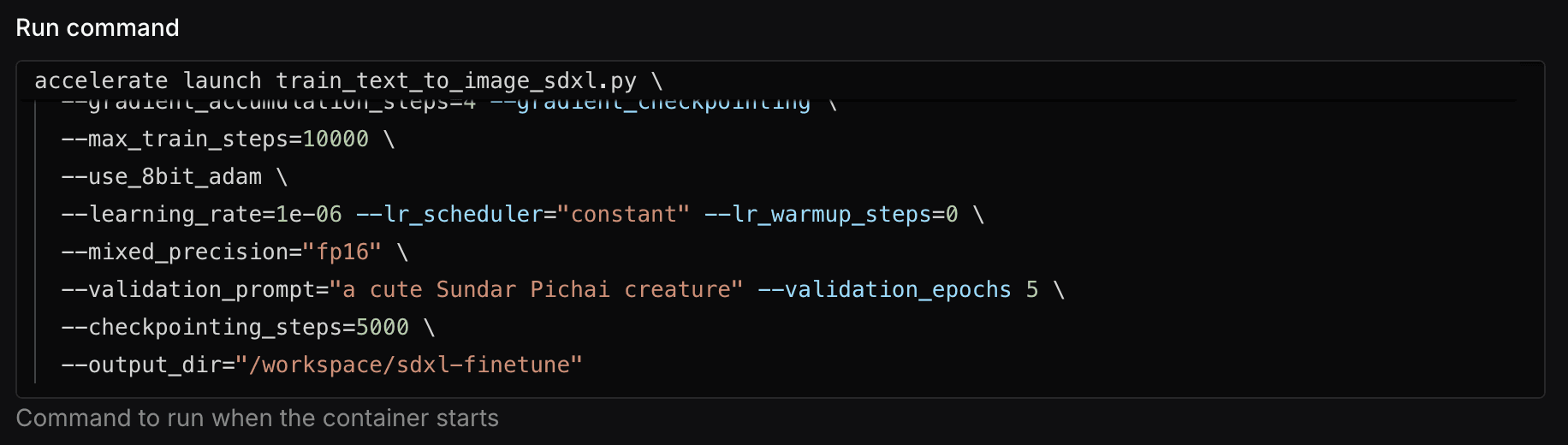
In the Run Command section, define the fine-tuning command, ensuring that the output_dir is set to /workspace/sdxl-finetune to match the directory you mounted earlier.
Here’s an example command for fine-tuning the SDXL model, where the output_dir is configured correctly:
# Clone the diffusers repository and install the required packages
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
# Use text-to-image example for fine-tuning
cd examples/text_to_image/
pip install -r requirements_sdxl.txt
pip install bitsandbytes
pip install torch==2.4.1 torchvision==0.19.1 -f https://download.pytorch.org/whl/torch_stable.html
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
export VAE_NAME="madebyollin/sdxl-vae-fp16-fix"
export DATASET_NAME="lambdalabs/naruto-blip-captions"
accelerate launch train_text_to_image_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--pretrained_vae_model_name_or_path=$VAE_NAME \
--dataset_name=$DATASET_NAME \
--resolution=512 --center_crop --random_flip \
--proportion_empty_prompts=0.2 \
--train_batch_size=8 \
--gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=10000 \
--use_8bit_adam \
--learning_rate=1e-06 --lr_scheduler="constant" --lr_warmup_steps=0 \
--mixed_precision="fp16" \
--validation_prompt="a cute Sundar Pichai creature" --validation_epochs 5 \
--checkpointing_steps=5000 \
--output_dir="/workspace/sdxl-finetune"
After entering the command, click on Create to launch the fine-tuning job.
Step 4: Monitoring Your Fine-Tuning Job
The fine-tuning job might take a couple of hours to complete, depending on the complexity of the task and the resources allocated. You can monitor the job status and logs to track its progress.
-
Job Details: Once created, follow the instructions on the modal to navigate to the job details page, where you can see the job status and information.

-
Check Logs: When the job status shows Running, you can monitor its progress by clicking Logs, and view the logs of each replica to track the fine-tuning process.

Step 5: Accessing the Fine-Tuned Model
After the fine-tuning job is completed, you can see the job status turns to COMPLETED, and you can access the trained model file in the storage page within the folder you just created in step 1.

That's it! You've now set up and finished a fine-tuning job using Lepton's Job module. Enjoy the streamlined workflow and the power of efficient long-running tasks execution!