Streamlined Fine-Tuning with Unsloth on Lepton
Lepton’s Job component simplifies one-time tasks, making it a powerful tool for streamlined model fine-tuning. In this guide, we demonstrate how to integrate Unsloth with Lepton’s job system to enhance productivity and simplify workflows.
Using this unsloth fine-tuning notebook as an example, we will fine-tune the LLaMA-3-8B model step by step.
Step 1: Prepare Your Unsloth Fine-Tune Script
To begin, create a Python script based on this unsloth fine-tuning notebook
Save it as unsloth-finetune.py.
from unsloth import FastLanguageModel
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
from datasets import load_dataset
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
# 4bit pre quantized models we support for 4x faster downloading + no OOMs.
fourbit_models = [
"unsloth/Meta-Llama-3.1-8B-bnb-4bit", # Llama-3.1 15 trillion tokens model 2x faster!
"unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
"unsloth/Meta-Llama-3.1-70B-bnb-4bit",
"unsloth/Meta-Llama-3.1-405B-bnb-4bit", # We also uploaded 4bit for 405b!
"unsloth/Mistral-Nemo-Base-2407-bnb-4bit", # New Mistral 12b 2x faster!
"unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit",
"unsloth/mistral-7b-v0.3-bnb-4bit", # Mistral v3 2x faster!
"unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"unsloth/Phi-3.5-mini-instruct", # Phi-3.5 2x faster!
"unsloth/Phi-3-medium-4k-instruct",
"unsloth/gemma-2-9b-bnb-4bit",
"unsloth/gemma-2-27b-bnb-4bit", # Gemma 2x faster!
] # More models at https://huggingface.co/unsloth
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
dataset = load_dataset("yahma/alpaca-cleaned", split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
# num_train_epochs = 1, # Set this for 1 full training run.
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none", # Use this for WandB etc
),
)
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.")
trainer_stats = trainer.train()
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory /max_memory*100, 3)
lora_percentage = round(used_memory_for_lora/max_memory*100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")
model.save_pretrained("lora_model") # Local saving
tokenizer.save_pretrained("lora_model")
Important Note:
During this example fine-tuning process, the dataset is created dynamically. However, if you prefer, you can upload your data to the workspace storage and place it at the same directory level as this script. You can then load the dataset from there in your script.
As indicated in the last two lines of code, the model will be saved in the script’s execution path by default. Alternatively, you can specify an path for saving the model. Make sure the specified path is within the mount directory, as any storage locations outside the mount path will be erased upon job completion.
Step 2: Setting Up the Input and Output Directory for Fine-Tuning Task
First, create a new folder in your Lepton workspace file system. This folder will serve as the input and output directory where all data, scripts, fine-tuning results are stored.
-
Access your workspace, then select "Utilities" from the navigation bar and click "Storage" in the dropdown. Alternatively, you can access your filesystem directly by clicking here.
-
In the action bar, click "New Folder" and name it according to your task. For instance, I will name mine
finetune.
Tip You could also use lep login and lep storage mkdir finetune to create this folder in your storage system.
- In this
finetunefolder you could clickupload fileto upload yourunsloth-finetune.py. hint You can also create a dedicated data folder within the finetune directory to upload your dataset files for easy organization and data import.
Tip You could also use lep storage upolad /path/to/your/local/unsloth-finetune.py /finetune/unsloth-finetune.py to upload this script to your storage system.
Step 3: Configuring Your Job
- Navigate to the Create Batch Job page.
- Assign a descriptive name to your job, such as
unsloth-finetune, and select an appropriate resource type based on your task requirements. For LLaMA-3 8B fine-tuning, resource options may include A100, or H100, depending on the model, dataset and workload. For this example, we’ll use H100. - Navigate to Advanced Settings and locate the File System Mount section. Click the Add File System Mount button. For Mount from, select the folder name you created earlier (e.g.,
finetunein this example). For Mount as, enter/workspace/finetune.
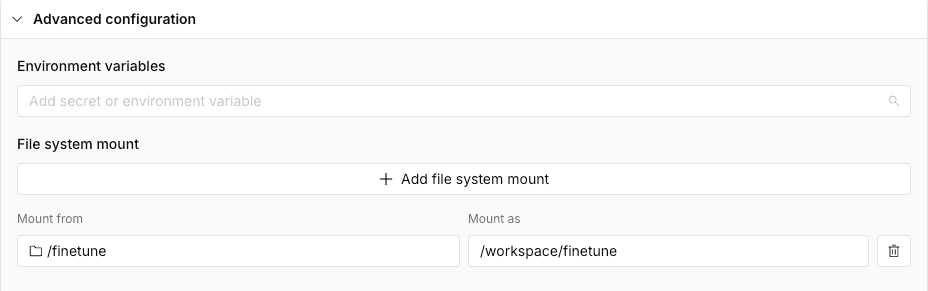
This configuration ensures that your finetune folder is accessible as the working directory during command execution, enabling seamless navigation and access to its contents.
Step 4: Specifying the Job Command
In the Run Command section, specify the command to execute the job. For this example, Since the job relies on a script, start by ensuring that all necessary dependencies for the script are installed beforehand. After that navigating to the script’s directory with cd finetune. Then, execute the script using python finetune.py, This ensures that the fine-tuning results are saved within the finetune folder.

Example Run Command for This Job:
pip install unsloth
pip uninstall unsloth -y && pip install --upgrade --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
pip install trl
pip install transformers
pip install unsloth
pip install datasets
pip install torchvision==0.20.1+cu124 torchaudio==2.5.1+cu124 --index-url https://download.pytorch.org/whl/cu124
cd /workspace/finetune
python finetune.py
Please note that here we used the following command to install specific versions of torchvision and torchaudio:
pip install torchvision==0.20.1+cu124 torchaudio==2.5.1+cu124 --index-url https://download.pytorch.org/whl/cu124
This is necessary because the default image includes torch==2.2.0, while unsloth requires torch>=2.4.0. Consequently, torch==2.5.1 was installed, requiring compatible versions of torchvision and torchaudio.
In the future, you may need to update this command to align with the latest torch version.
After entering the command, click on Create to launch the fine-tuning job.
Step 5: Monitoring Your Fine-Tuning Job
The fine-tuning job might take a couple of hours to complete, depending on the complexity of the task and the resources allocated. You can monitor the job status and logs to track its progress.
-
Check Logs: When the job status shows Running, you can monitor its progress by clicking Logs, and view the logs of each replica to track the fine-tuning process.
