Job Failure Diagnose
Lepton AI provides a built-in feature to automatically diagnose job failure. This feature is designed to help users quickly identify and resolve issues in batch jobs, ensuring optimal performance and reliability.
Let's walk through an example of how to use this feature to diagnose a job failure.
Prepare a Job Designed to Fail
First we need to create a job that will fail for testing. The following script will create a memort leak on a GPU by continuously allocating tensors using Pytorch and preventing them from being garbage collected, until it reaches a target memory usage (defaulting to 10GB but configurable via command line).
import torch
import time
import argparse
import sys
def create_gpu_memory_leak(target_gb=10):
if not torch.cuda.is_available():
print("No GPU available. Exiting.")
return
print(f"Starting GPU memory leak test (target: {target_gb}GB)...")
stored_tensors = [] # List to prevent garbage collection
try:
while True:
# Create a 1GB tensor (approximately)
# Using float32 (4 bytes) * 250M elements ≈ 1GB
tensor = torch.rand(250_000_000, device='cuda:0')
stored_tensors.append(tensor) # Prevent garbage collection
current_memory = torch.cuda.memory_allocated('cuda:0') / (1024**3) # Convert to GB
print(f"Current GPU memory usage: {current_memory:.2f} GB")
if current_memory > target_gb: # Use the target parameter
print(f"Reached {target_gb}GB memory usage target")
break
time.sleep(0.1) # Small delay to prevent system from becoming unresponsive
except KeyboardInterrupt:
print("\nTest interrupted by user")
finally:
print("Test completed")
if __name__ == "__main__":
# python bad_job.py -t 100 for 100GB target
parser = argparse.ArgumentParser(description='GPU Memory Leak Test')
parser.add_argument('-t', '--target', type=float, default=10,
help='Target memory usage in GB (default: 10)')
args = parser.parse_args()
create_gpu_memory_leak(args.target)
Save the script as bad_job.py and upload it to the Lepton file system. using the following command:
lep storage upload bad_job.py
Create the Job
Navigate to the Batch Jobs page to create the job with the following configuration:
Resource
As we just want to test the job failure diagnosis feature, we can create a job with any desired GPU card and corresponding node group.
Container
In the container section, we will use the default image and paste the following command to run job:
python /mnt/bad_job.py -t 100 gigabytes # 100GB target memory usage
File System Mount
Open the Advanced configuration and click Add file system mount.
In the "Mount from" part, choose the default path as we have uploaded the file to the default storage area, then specify /mnt in the "Mount as" section.
Create the Job
Click Create to create the job. Once the job is created, you can view the job in the Lepton Dashboard.
Diagnose Job Failure
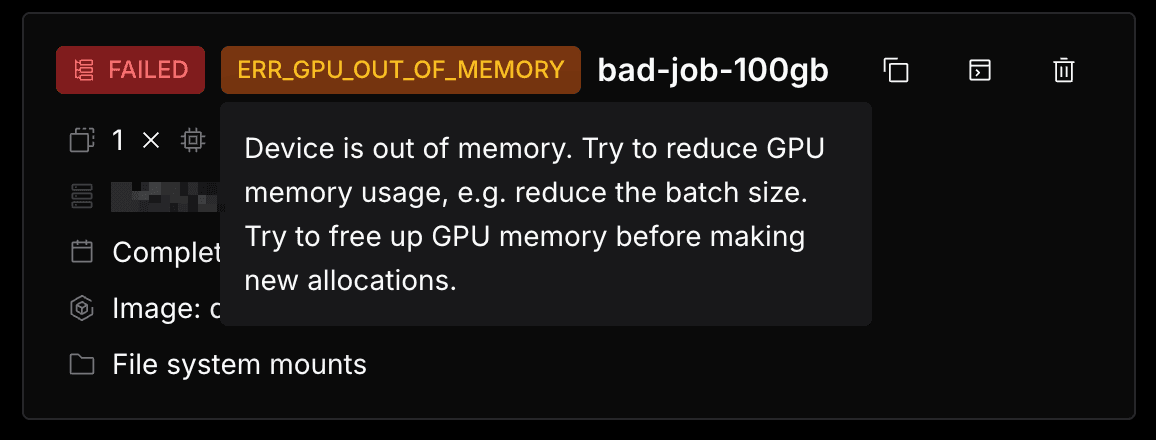
The job will fail after reaching the target memory usage. And then you will see a failure message in the job details page.
And for this example, you will see an error tag to show the job is failed due to ERR_GPU_OUT_OF_MEMORY.
Hover over the error tag, you will see the detailed error message.