Serverless Endpoints
Built on top of the Lepton platform, we provide a variety of serverless endpoints for popular open source models.
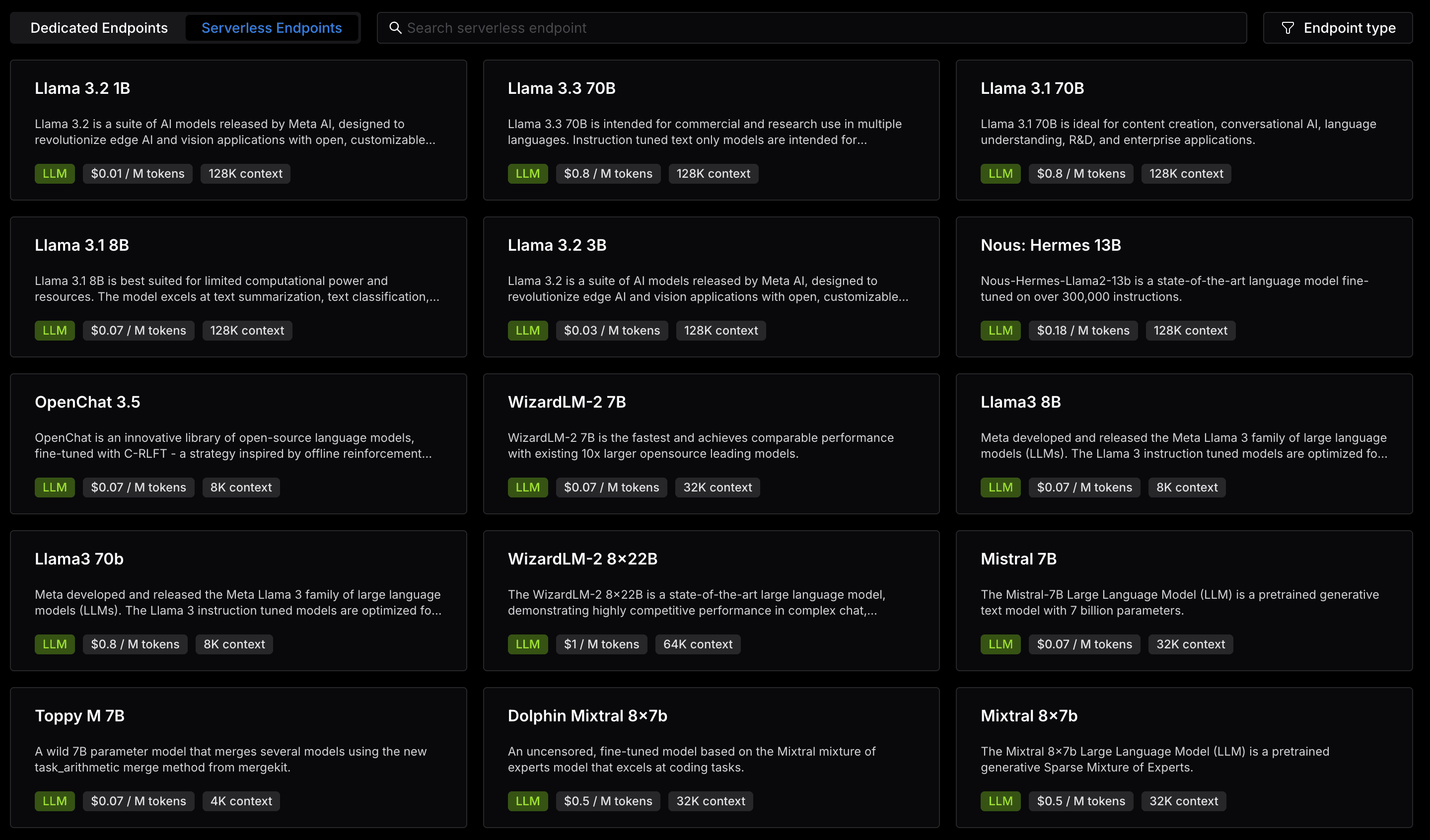
What are Serverless endpoints?
Serverless endpoints are pre-configured endpoints by Lepton AI for you to get started quickly. They are designed to be simple and easy to use, and are a great way to get started with Lepton AI.
You can try out the best open source LLMs like Llama 3.1 70B, Mixtral 8x7B, use Whisper to transcribe audios, or create videos and images with Stable Diffusion models.
How to use Serverless endpoints?
Our LLM Serverless endpoints are all fully compatible with OpenAI's API spec, you can use them in the same way as OpenAI API. Let's take Python SDK and Mistral 7B as an example.
1. Install the OpenAI Python SDK.
pip install openai
2. Setup environment variables and initialize the client.
import openai
import os
client = openai.OpenAI(
base_url="https://mistral-7b.lepton.run/api/v1/",
api_key=os.getenv("YOUR_LEPTONAI_TOKEN")
)
You can get your LeptonAI token in your workspace settings page.
3. Use the endpoint in your code.
response = client.chat.completions.create(
model="mistral-7b",
messages=[{"role": "user", "content": "Hello, world!"}],
max_tokens=128,
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content)
You can find more Serverless endpoints in the reference page.
Usage
Lepton will record the usage of each Serverless endpoint, you can see a detailed usage statistics in the usage of the endpoint, including the requests and tokens.
Rate Limits
There are different rate limits for users on different plans:
- Basic Plan: 10 Requests per minute.
- Pro Plan: 600 Requests per minute.
- Enterprise Plan: Contact us to get a custom rate limit.
Billing
Each Serverless endpoint has a unique pricing since the underlying model and hardware are different, while all the endpoints are charged by usage. You can see the pricing details in the Serverless endpoint list and each endpoint details page.
You can check the details in the Pricing page.
Playground
We also provide a playground for you to quickly try out the endpoint. In this section, we will use the Serverless endpoint for Llama 3.1 70B as an example.
Chat Playground
Playground is for you to quickly try out the endpoint without any setup.
You can modify the modal parameters like Temperature, Top P, etc, you can also use voice output with your favorite voice assistant.
There is also a Schema playground for you to understand the input and output schema of the endpoint so that you can use it in your own application easily.
API
If you are satisfied with the model and parameters you just tried, you can then use the API request to get the same result in your own application.
Switch to the API tab, you can get your API token, learn a simple code demo and see the detailed API reference for you to use this endpoint in your own application.
What's Next?
If Serverless endpoints can't meet your requirements, you can also run models with a dedicated endpoint. For how to create a dedicated endpoint, you can get a detailed guide here.